Dimensionality Reduction
Curse of Dimensionality
Dimension이 커질 수록 데이터가 sparse하게 분포하게 된다.
이로 인해 차이가 큰 object와의 거리와 차이가 작은 object와의 거리가 크게 차이나지 않게 된다.
때문에 dimension을 줄일 필요가 있다.
Dimensionality Reduction의 장점
- curse of dimensionality를 피할 수 있다.
- irrelevant feature을 제거할 수 있다.
- noise를 줄일 수 있다.
- data mining에 필요한 time과 space를 줄일 수 있다.
- visualization이 쉬워진다.
방법
- Wavelet transforms
- principal component analysis (PCA)
- attribute subset selection
Wavelet Transformation
Discrete Fourier Transformation(DFT)와 유사하지만 DFT에 비해 attribute가 덜 버려진다.
- Discrete wavelet transformation(DWT)
- Compressed approximation
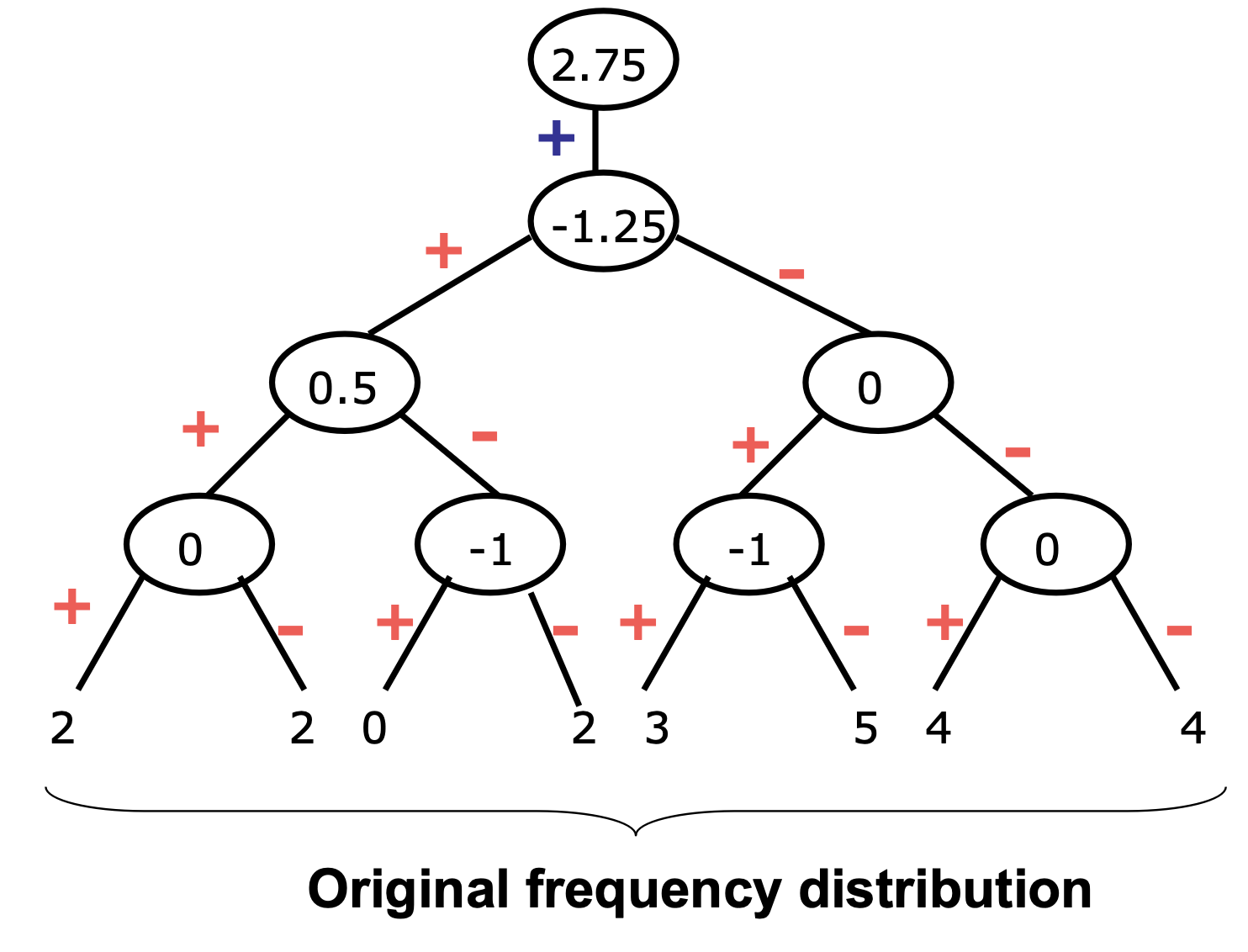
Wavelet Decomposition
Space-efficient hierarchical decomposition을 위한 수학적인 도구이다.
원본으로 복구가 가능하도록 만들어지며 어떤 것이 중요한 값인지 알 수 있다.
아래와 같이 수행하면 결과적으로 $S = [2 \frac{3}{4}, -1 \frac{1}{4}, \frac{1}{2}, 0, 0, -1, -1, 0]$이 나온다.

Hierarchical Decomposition Structure
= Error tree
= Harr Wavelet Coefficients
Wavelet coefficients를 tree 구조로 표현할 수 있다.
적당한 level에서 자르면 중요한 정보를 유지하면서 compression 할 수 있다.
Principal Component Analysis (PCA)
차원의 정의를 바꿈으로써 유사한 차원을 줄이는 방법이다.
이를 통해 주요 components를 찾을 수 있다.
Original data가 더 작은 차원으로 투영된다.
결과적으로 dimensionality reduction이 수행되는 것이다.
단, numeric data에만 적용할 수 있다.
방법
- input data를 normalize한다. → 각 차원이 같은 range로 떨어지도록 한다.
- k orthonormal vector를 계산한다.
- principal components 찾기
- 원래 object 간의 distance를 유지하면서도 correlation이 없도록 하는 n차원으로 변환한다.
- 차원이 유지됨
- 중요도(어떤 dimension에서 데이터가 더 퍼져있는가)를 기준으로 정렬하여 k개만 선택한다.
- weak components(중요도가 적은 차원)을 줄임으로써 데이터의 크기가 줄어든다.
- → $n-k$-dimension이 줄어든다.
- principal components 찾기
Attribute Subset Selection
데이터를 변환하지 않고 중요한 attribute만 선택하는 방법이다.
Redundant하거나 irrelevant한 dimension을 제거한다.
- Original : d-dimension이 있을 때 가능한 attribute의 조합은 $2^d - 1$개 이다.
- Best single attribute
- 각 attribute가 독립이라고 가정하고 하나의 attribute만을 선택했을 때 괜찮은 결과물을 내는 것을 찾는다.
- → redundant을 제거할 수 없다.
- Best step-wise feature selection
- 확장해나가면서 좋은 attribute의 조합을 찾는다.
- cost : $O(d^2)$ → 하나와 다른 하나의 비교
- 방법
- best single-attribute A를 선택한다.
- A와 다른 attribute를 결합했을 때 가장 좋은 결과를 내는 attribute B를 선택한다.
- 반복적으로 계속 확장해나간다.
- Step-wise attribute elimination
- 전체를 사용했을 때에서 어떤 attribute를 뺄지를 선택해나간다.
'Computer Science > Data Science' 카테고리의 다른 글
| [Data Reduction] Data Compression (0) | 2022.06.13 |
|---|---|
| [Data Reduction] Numerosity Reduction (0) | 2022.06.13 |
| [Data Processing] Data Reduction (0) | 2022.06.12 |
| [Data Processing] Data Integration (0) | 2022.06.12 |
| [Data Processing] Data Cleaning (0) | 2022.06.12 |




댓글