DCGAN
GAN의 변형으로 그림을 만드는데 주로 이용한다.
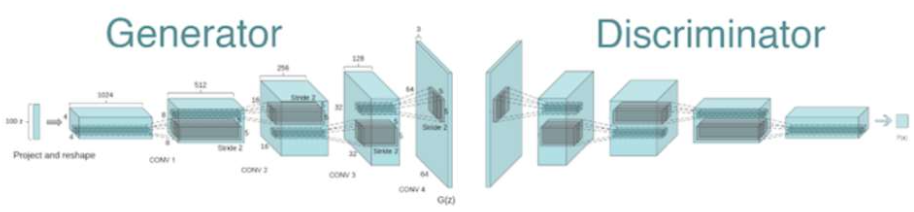
구조
- Generator
- transposed convolution으로 구성
- convolution operation 뒤에 batch norm 적용
- hidden layer - ReLU / output layer - tanh
- Discriminator
- strided convolution으로 구성
- convolution operation 뒤에 batch norm 적용
- hidden layer - LeakyRelu
천천히 변하는 이미지
Z가 조금 바뀌면 결과물도 조금 바뀌는 특성을 이용한다.
Random noise를 2개 생성하고 그 2개에 대한 interpolation을 input으로 넣는다.
Image에 대한 interpolation이 아닌 z(input)에 대한 interpolation을 함으로써 천천히 변하는 결과물을 얻을 수 있다.

두 이미지 합치기
두 z를 더하고 뺌으로써 원하는 결과물을 만들어낼 수 있다.

Laplacian Pyramid GAN
Scale을 조금씩 키워나가면서 이미지의 quality를 높인다.
한번에 확 키우는 것보다 더 수월하게 quality를 높일 수 있다.
다만 과정의 architecture가 복잡하고 시간이 더 오래 걸릴 수 있다.
예시

Conditional GAN (cGAN)
특정 condition의 더 다양한 이미지를 생성할 수 있다.
Input으로 random noise Z 외에도 추가적인 정보를 넣는다.
만들어진 이미지와 class가 동일한 이미지와 비교함으로써 해당 class(condition)의 이미지를 생성할 수 있다.
Objective function에 하나의 input이 더 들어간다.
$min_G max_D V(D, G) = E_{x \sim p_{data}}[log(D(x, y))] + E_{x \sim p_G}[log(1-D(G(x, y)))]$

Pix2Pix Image
이미지 변환을 위해 주로 사용되는 cGAN의 변형이다.
예를 들어 지도 → 항공뷰로의 변환을 하거나 스케치 → 컬러가 입혀진 이미지로의 변환 등의 작업을 할 수 있다.
Condition으로 이미지를 넣는다.
단, x와 y가 pair로 데이터셋에 존재해야 한다.
$min_G max_D L_{cGAN}(G, D) + \lambda L_{L1}(G)$
$L_{cGAN}(G, D) = E_{x \sim p_{data}}[log(D(x, y)))] + E_{x \sim p_G}[log(1-D(x, G(x, y)))]$
$L_{L1}(G) = E_{x, y, z}[|| y - G(x, z) || _1 ]$ → 얼마나 realistic한가
$\lambda = 100$

결과
L1만 이용하면 realistic하기만하면 되고 input과 유사하지는 않아도 된다.
반면 cGAN만 이용하면 input과 유사하기만 하면 되고 realistic하지는 않아도 된다.
그런데 cGAN + L1을 같이 사용하면 input과 유사하면서도 realistic한 결과를 얻을 수 있다.

Pix2Pix의 단점
Pix2Pix에서 x와 y가 pair로 데이터셋에 존재해야한다.
그런데 pair로 데이터셋을 준비하기는 쉽지 않다.
Cycle GAN
(x, y)가 pair로 데이터셋에 존재해야하는 문제를 해결한다.
X → Y, Y → X를 만드는 2개의 generator를 둔다.
이를 통해 서로가 서로를 만들도록 함으로써 (x, y) 중 하나만 데이터셋에 존재하면 된다.
원래대로 같게 돌아가기를 목적으로 하기 때문에 원본의 정보가 최대한 유지되어야 한다.
따라서 바뀌는 부분(오브젝트)을 제외한 나머지 부분(잔디, 하늘 등)은 거의 바뀌지 않는다.


SRGAN (Super-Resolution GAN)
GAN을 이용하여 이미지의 quality를 높이는 task를 수행한다.
GAN의 결과가 다른 것에서부터 나온 것에 비해 더 그럴듯 해 보이지만 실제 결과와는 다를 수 있다.
어디까지나 fake image를 만들어낸 것이기 때문이다.
실제로 ground truth(SSIM)의 값은 다른 방법으로 만들어낸 값보다 좋지 않을 수 있다.
그러나 사람이 자연스럽다고 느끼는 수치(MOS)는 다른 방법에 비해 높은 편이다.

Style GAN
훨씬 더 크고 그럴듯한 결과물을 만들어낸다.
기존에는 random noise를 CNN에 넣어서 G를 구성했다.
그러나 style GAN은 앞에 DNN을 넣어서 gaussian distribution이 좋아하는 noise로 바꾸고 이를 CNN에 넣는다.

'Computer Science > AL, ML' 카테고리의 다른 글
| [CNN] 더 나은 모델을 위한 테크닉들 (0) | 2022.06.16 |
|---|---|
| [Generative Model] GAN : Generative Adversarial Networks (0) | 2022.06.16 |
| Generative Model (0) | 2022.06.16 |
| [CNN] Model Understand (0) | 2022.06.16 |
| [CNN] Image Captioning & Attention (0) | 2022.06.16 |




댓글