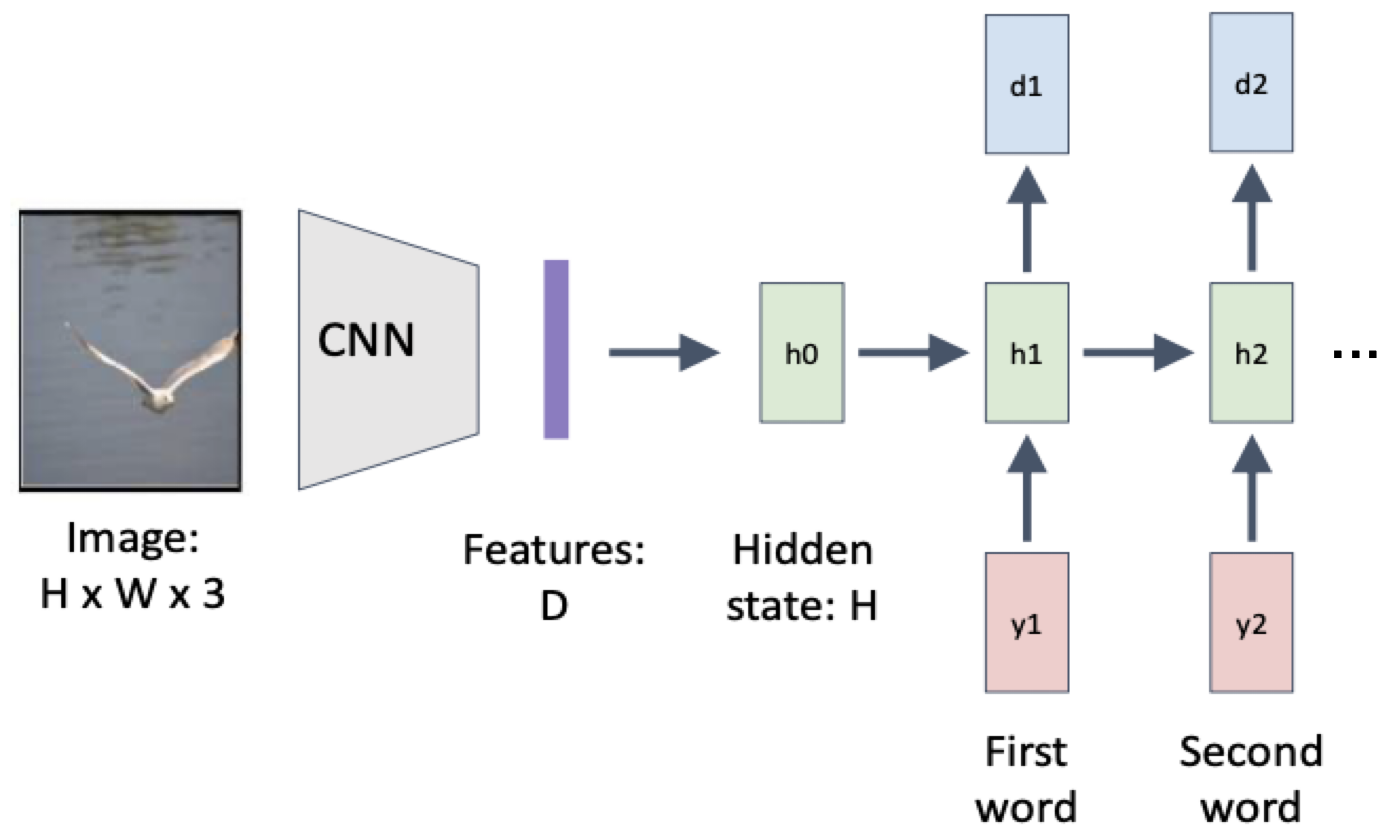
Image Captioning
주어진 image에 대해 묘사하는 string을 만들어내는 작업을 image captioning이라 한다.
이를 위해 CNN + RNN을 결합하여 모델을 구성한다.
CNN을 통해서 visual information을 뽑아내어 feature vector를 만들고, RNN을 이용하여 그 정보들을 합쳐서 단어 sequence를 만들어 내는 것이다.
CNN + RNN의 단점
그런데 이 경우 RNN은 배경, 몸짓, 특징 등 세부적인 것을 보고 판단하지 않고 전체 이미지를 한 번에 살펴보고 판단하게 된다.
더 local하게 살펴본 결과를 얻기 위해 attention이라는 기법을 사용하게 된다.
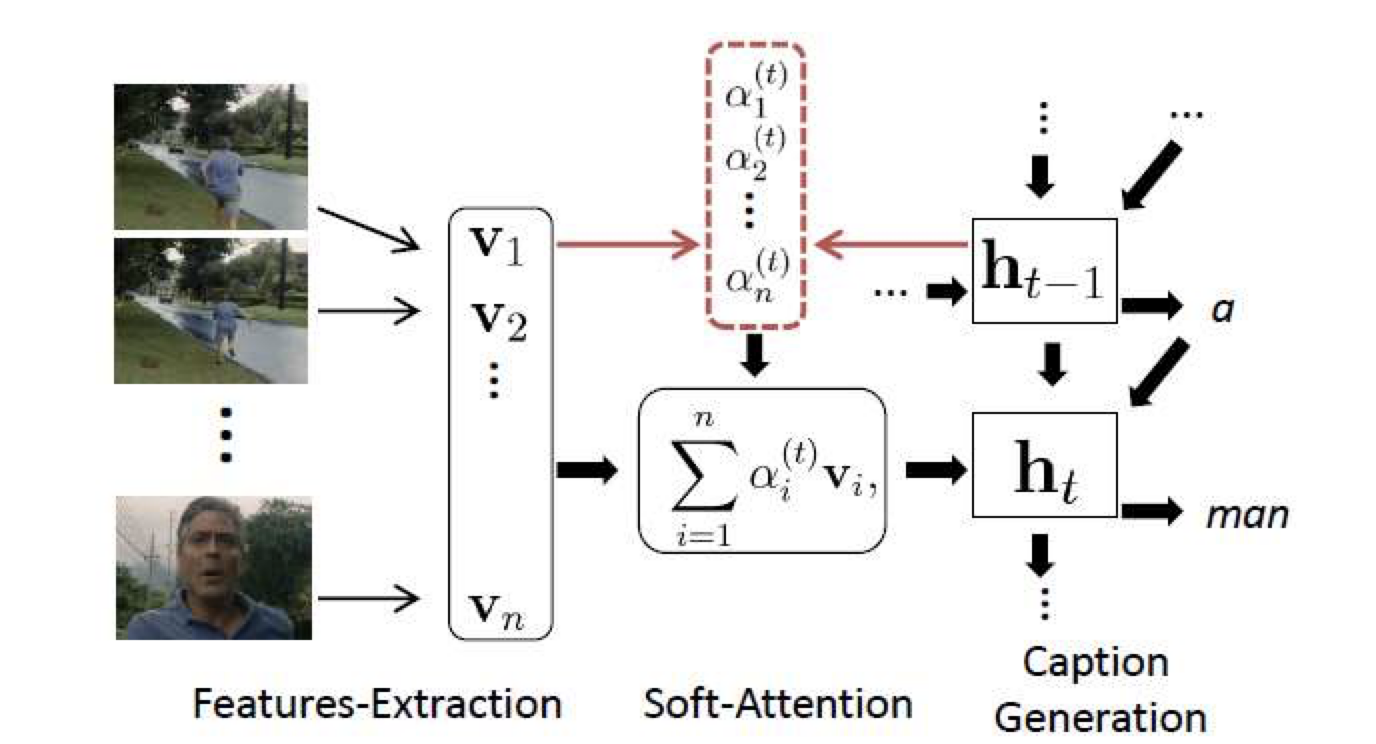
Attention
Image captioning을 위해 자주 사용되는 기법이다.
Image의 local한 영역을 살펴보고 이미지에 대한 묘사를 만들어 낼 수 있다.
방법
- CNN으로부터 feature를 뽑는다. → flatten하지 않고 그대로 사용
- RNN을 통해서 단어를 순차적으로 생성해나간다.
- 어떤 단어 하나가 생성되면 어떤 파트를 보고 그 단어를 만들었는지 모델에 알려준다.
- RNN은 그 부분에 대한 정보를 또 다시 다음 input으로 함께 넣는다.

Soft Attention vs. Hard Attention
- Soft attention
- $z = p_a a + p_b b + p_cc + p_dd$
- 다른 region의 정보가 섞일 수 있다.
- 계산 cost가 낮다.
- Hard attention
- argmax를 이용하여 하나의 region에 대한 p값만 1로 하고 나머지는 0으로 한다.
- 즉, 가장 큰 region만 뜯어서 확인하게 된다.
- 정확도가 더 높다.
- argmax는 미분이 불가능하기 때문에 backpropagation이 불가능하다.
따라서 reinforcement learning(강화학습)을 이용해야 한다. - 계산 cost가 높다.

아래 그림은 soft attention과 hard attention에서 학습에 이용한 region 정보를 하얀색으로 칠한 것이다.
Hard attention은 하나의 region만 보는 반면, soft attention은 여러 region을 보는 것을 확인할 수 있다.

Soft Attention For Video Captioing
Image captioning 뿐만 아니라 video captioning에도 이용이 가능하다.
주요 장면의 컷(이미지)를 데이터로 넣어 문장을 만드는 방법을 이용한다.
'Computer Science > AL, ML' 카테고리의 다른 글
| Generative Model (0) | 2022.06.16 |
|---|---|
| [CNN] Model Understand (0) | 2022.06.16 |
| [RNN] GRU (Gated Recurrent Unit) (0) | 2022.06.16 |
| [RNN] LSTM (Long Short-Term Memory Network) (0) | 2022.06.16 |
| [RNN] Vanilla RNN (0) | 2022.06.15 |




댓글