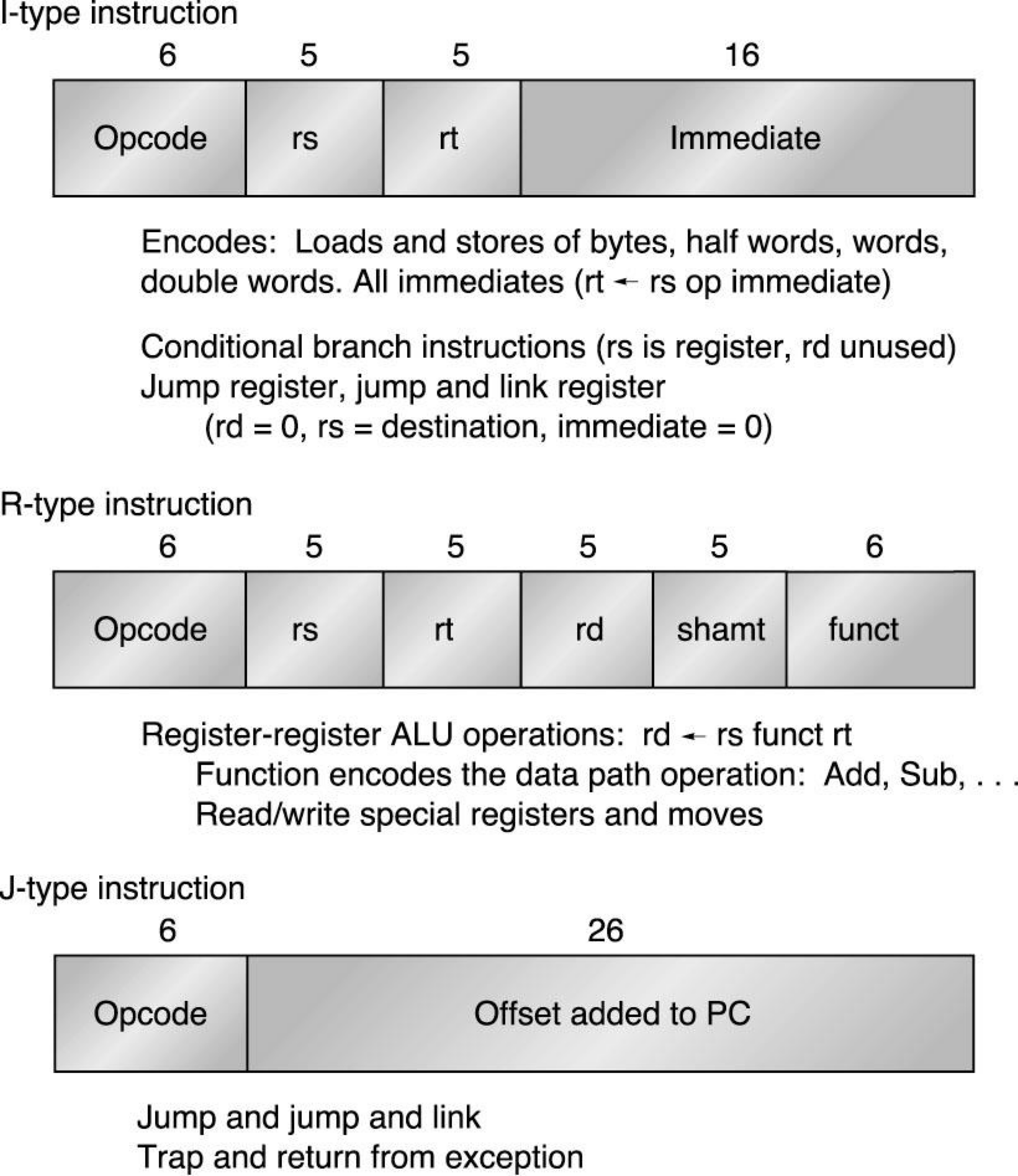
Instruction Format
ENIAC은 아니었지만 현대의 컴퓨터는 모두 stored program computer이다.
따라서 프로그램은 컴퓨터에 저장된다.
이를 위해서 instruction은 binary instruction(machine code)로 변환되어야 한다.
MIPS는 32-bit instruction word로 encode된다.
이를 위해 32-bit instruction을 어떻게 나눠서 opcode, operand 등을 encoding 할 것인지 결정해야 한다.
MIPS는 3종류의 구조가 있고, I-type instruction, R-type instruction, J-type instruction이다.
| Format | Operand 개수 | Operand 구성 | Instructions |
| I-type | 2 | 1 destination + 1 source |
lw / sw (Base addressing) addi (Immediate addressing) bne, beq (PC-relative addressing) |
| R-type | 3 | 1 destination + 2 source |
add (Register addressing) jr, jalr slt, slti, sltu, sltui |
| J-type | 1 | 1 PC-relative offset | j, jal (Pseudo-direct addressing) |
Format을 최대한 적게 해야하는 이유?
다른 format은 각각 처리할 하드웨어를 따로 필요로 한다.
또한 format의 종류가 다양하면 decoding하는 과정이 복잡해진다.
따라서 최대한 적고 단순한 format을 사용하는 것이 유리하다.
Good Choice
instruction의 각 부분의 길이(opcode, register, funct, immediate 등)가 어느 것이 더 좋을지 판별하는 것은 HW-SW interaction와 같다.
즉 여러 경우에 대해 구현해서 벤치마크 프로그램을 돌린 후 어느 것이 더 빨리 돌아가는 가를 파악하는 것이다.
더 빨리 돌아가는 것이 더 좋은 성능을 나타낸다.
R-Type Instruction
Register 기반의 register-based ALU instruction와 jr(unconditional jump register) instruction 사용한다.
Register addressing mode을 사용한다.
Operation은 6bit, register는 5bit을 사용한다.
32-bit computer에서 register는 32개가 존재하므로 5bit만으로도 충분하다.
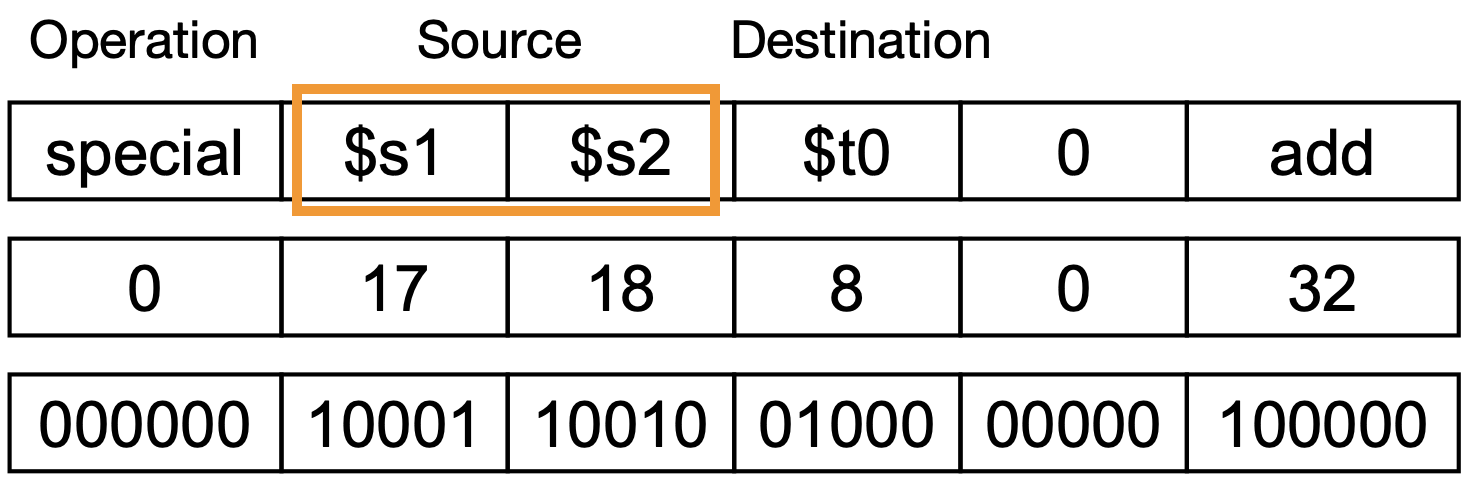
어셈블리 코드는 destination first이지만 machine code에서는 source first이다.
이는 어셈블리는 순전히 mnemonic을 위한 것이며, source first인 것이 하드웨어의 구현이 쉽기 때문이다.

- op : operation code(opcode)
- rs : first source register number
- rt : second source register number
- rd : destination register number
- shamt : shift amount
- funct : function code (extends opcode)
Function code가 존재하는 이유?
실제 컴퓨터에서 operation은 $2^6(=64)$개보다 훨씬 많다.
때문에 opcode을 최대한 절약해야 하기 때문에 ALU instruction은 opcode가 모두 0이다.
Instruction의 자세한 구분은 function code(funct)을 통해서 이루어진다.
Register-based ALU instruction은 모두 opcode는 같지만 funct는 다른 형태를 띈다.
다른 format의 instruction들도 opcode의 길이가 동일하다.
만약 funct를 없애고 opcode를 늘리게 되면 다른 용도로 사용할 bit가 줄어들기 때문에 하지 않는다.
예시
<pre>add $t0, $s1, $s2</pre>
어셈블리 코드에서는 destination인 <pre>$t0</pre>가 먼저 왔지만, machine code에서는 source first이기 때문에 <pre>$t0</pre>는 맨 뒤로 빠진 것을 볼 수 있다.
I-Type Instruction
아래 instruction들이 사용한다.
- Data transfer instruction
- base addressing
- load, store
- ALU instruction
- immeidate addressing
- addi
- Branch instruction
- bne, beq
opcode, 2개의 register, 16bit의 immediate(constant)가 포함되어있다.

- op : operation code
- rs
- lw(load)에서는 source
- sw(store)에서는 destination
- rt
- load에서는 destination
- store에서는 source
- Constant
- $-2^15 ~ 2^15-1$
- 더 큰 범위의 상수일 경우 특수한 opcode를 사용한다.
Immediate
레지스터는 들어있는 값을 가져와야하기 때문에 메모리에 한번 갔다와야 한다.
그러나 상수는 메모리에 갔다올 필요 없이 바로 그 자체가 값이다.
즉 값을 바로 확인할 수 있다는 의미에서 offset 등의 상수를 immediate라고 한다.
상수 부분(immediate)이 클수록 표현 범위가 늘어나기 때문에 유리하다.
따라서 opcode와 register을 제외한 모든 부분을 immediate가 사용한다.
가능한 한 많은 부분을 constant가 사용한다.
16bit보다 더 많거나 더 적은 bit를 사용하는 것보다 16bit을 사용하는 것이 벤치마크 프로그램을 돌려서 성능을 비교함으로써 더 좋은 것임을 확인할 수 있다.
register의 bit수나 opcode의 bit수 또한 현재의 형태가 가장 최선임을 벤치마킹을 통해 확인할 수 있다.
Sign Extension, Unsigned Extension
레지스터에 대한 offset 차이는 ALU를 통해서 이루어진다.
그런데 ALU는 32bit이므로 32bit끼리의 연산만 가능하다.
그러나 offset은 immediate 부분에 저장되므로 16bit이다.
따라서 연산을 위해서는 16bit을 32bit으로 늘려야 한다.
Sign extension이란 값을 그대로 유지하면서 bit을 늘리는 것을 말한다.

unsigned의 경우 앞의 추가적인 bit를 0으로 채우면 된다.
그러나 signed number는 음수에 대한 값을 그대로 유지해야 하기 때문에 앞의 추가적인 bit을 1로 채워야 한다.
즉 맨 앞의 bit(MSB)를 복제해서 길이를 늘리면 된다.

J-Type Format
Unconditional jump instruction(<pre>j, jal</pre>)이 사용한다.
1개의 operation과 1개의 immediate로 이루어져있다.

Destination Address
word 단위로 표현된다.
jump는 instruction 단위로 이루어지기 때문에 맨 하위 2bit는 항상 00이다.
낭비를 없애고 더 많은 표현 범위를 가지기 위해서 address의 하위 2bit는 생략된다.
이렇게 함으로써 28bit의 표현범위를 가질 수 있다.
Address는 32bit이므로 상위 4개의 bit는 현재 PC값의 상위 4bit을 그대로 이용한다.
Addressing Mode
어떤 operand를 어떻게 사용할 것인가를 말한다.
Common operation을 single instruction으로 만들기 위한 것이다.
Immediate, Register, Base, PC-relative, Pseudodirect addressing이 있다.

Immediate addressing mode
constant에 대해서 sign extension, unsigned extension이 일어난다.
Register addressing mode
모든 operand는 register만이 가능하다.
Base addressing mode
= Offset addressing mode
기준 register(base) + offset을 같이 제공한다.
상대적인 위치(base addressing mode)를 이용하지 않고 absolute address를 사용할 경우 instruction의 길이가 32bit을 넘어선다.
이는 RISC style이 아니며, 32bit의 길이를 맞춰줄 경우 instruction이 2개의 word에 저장되기 때문에 fetch를 두 번 수행해야 한다.
이는 성능의 저하를 일으킨다.
PC-relative addressing mode
PC(program counter)를 기준으로 상대적인 위치를 사용한다.
bne, beq의 unconditional jump instruction이 PC-relative addressing mode를 사용한다.
Jump는 instruction 단위, 즉 word 단위로 발생하기 때문에 offset의 맨 마지막 두 비트는 00이 된다.
이는 bit의 낭비이므로, 낭비를 없애고 표현범위를 늘리기 위하여 맨 마지막 두 bit를 생략하여 word 단위로 사용한다.
Pseudo-direct addressing mode
Unconditional jump instruction(<pre>j</pre>)가 pseudo-direct addressing mode이다.
Pseudo-direct란, direct에 준하여 사용된다는 의미로, full 32bit address를 사용하여 jump하는 것은 아니지만 이와 유사하다는 의미이다.
Direct와 유사하게 32bit address 중 하위 28개의 bit을 이용하여 jump을 수행하며, 상위 4개 bit는 current PC의 상위 4bit을 이용한다.
Jump는 word 단위이므로, 하위 2bit을 생략하여 표현한다.
Dynamic library는 프로그램 실행 중에 들어오는 부분으로, address의 시작주소 4bit는 0000이 아니다.
때문에 target address 상위 4bit을 0000으로 제한하게 되면 dynamic library로써는 사용할 수 없다.
따라서 dynamic library를 포함하여 더 넓은 범위에서 사용하기 위해서 상위 4bit을 current PC의 상위 4bit로 사용한다.
28bit을 이용하면 text segment에서 어디든지 jump 할 수 있다.
다만 code에서 dynamic library로의 jump는 불가능하다.
이는 jr(jump register)을 이용해야한다.

'Computer Science > Computer Architecture' 카테고리의 다른 글
| 2. MIPS : Control Instruction (2) | 2021.04.20 |
|---|---|
| 2. MIPS : ALU and Data Transfer Instruction (0) | 2021.04.17 |
| 2. MIPS Instruction Set (0) | 2021.04.17 |
| 1. Multicore (0) | 2021.04.10 |
| 1. Good ISA (0) | 2021.04.10 |




댓글