Direct Map Cache
Cache design issue들을 해결하는 가장 간단한 방법이다.
가장 간단(단순)하기 때문에 빠르다.
Cache의 속도(hit time)가 processor의 clock speed(cct)를 결정한다.
Direct mapping은 빠른 방법이기 때문에 cct가 가장 빠르다.
Placement (Mapping)
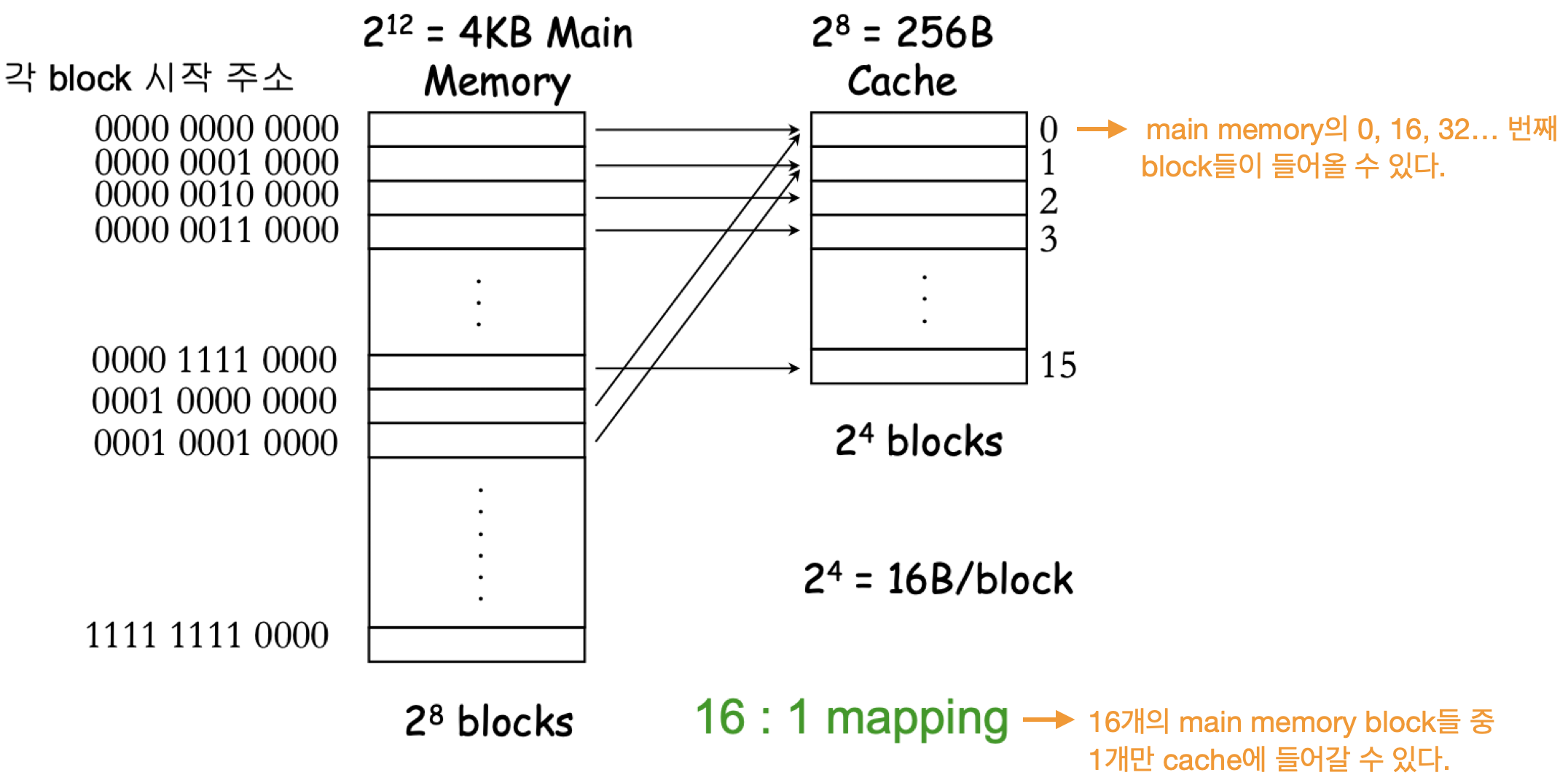
Main memory의 각 block들이 cache에 들어갈 자리가 미리 정해져 있다.
Cache의 각 block에는 하나의 block만 들어올 수 있다.
Identification
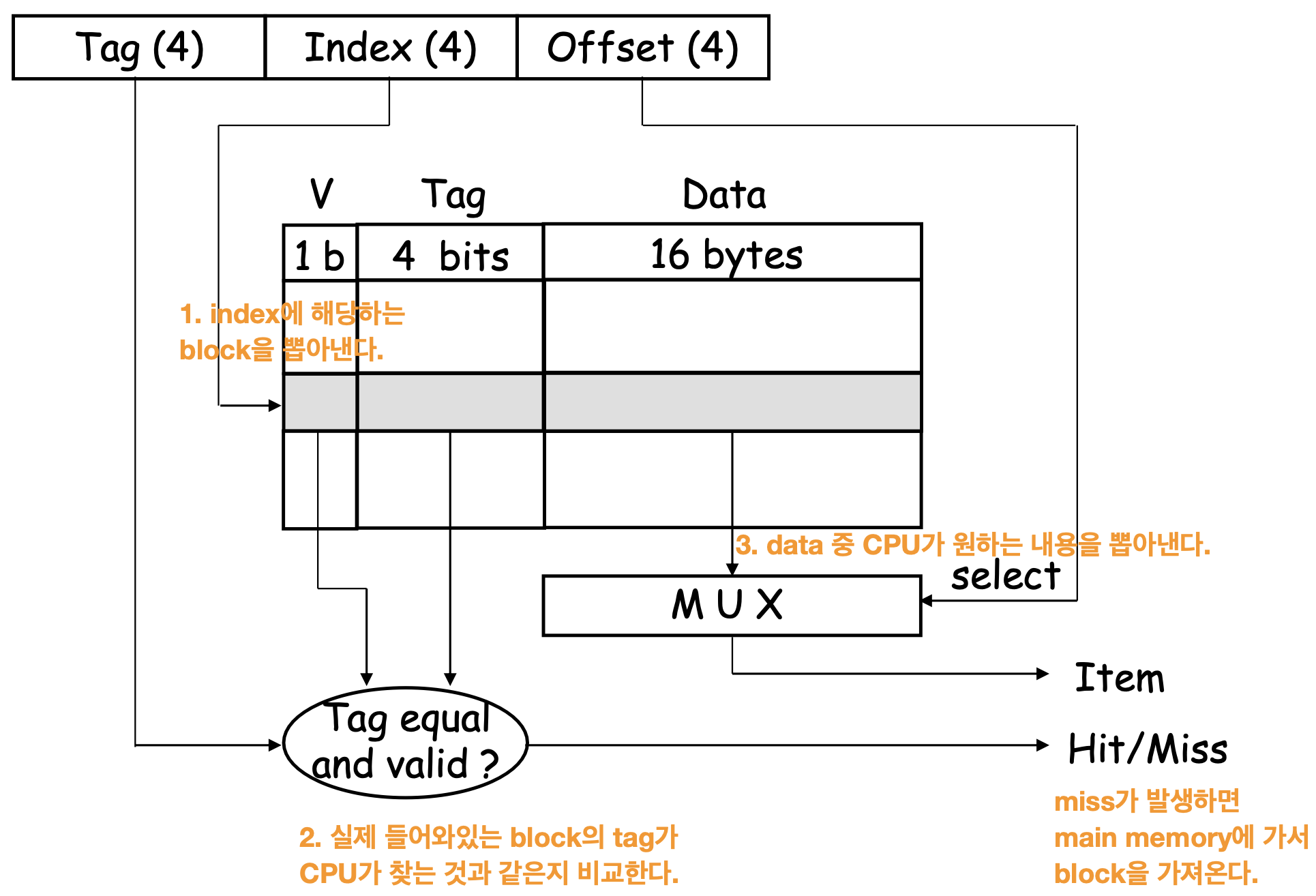
CPU의 주소는 다음과 같이 구성된다.
- tag
- cache의 각 block에 들어갈 수 있는 main memory의 block들 중 몇 번째 인가
- index
- cache에서 몇번째 block을 찾아야 하는가
- cache에서의 index
- byte offset
- 한 block 내에서 몇 번째 위치인가
- cache에서 block을 찾은 후 해당 block 내에서의 위치를 표현한다.
- 따라서 identification을 판단할 때에는 필요하지 않다.

Replacement Policy
무조건 자신이 들어갈 위치에 있는 block을 제거한다.
따라서 replacement를 고려하지 않아도 된다.
그러나 address conflict의 문제가 발생한다.
Address Conflict
Cache의 한 위치에는 하나의 block만이 들어갈 수 있다.
자주 사용하는 다수의 block이 하나의 같은 위치로 mapping 된다면 계속 miss가 발생하면서 block이 교체 될 것이다.
이는 miss rate의 증가를 일으키고 성능을 떨어뜨린다.
이렇게 2개의 block이 하나의 위치로 mapping 되면서 발생하는 문제를 2-way address conflict라고 한다.
만약, 3개의 block이 하나의 위치로 mapping되면서 문제가 발생한다면 3-way address conflict라고 한다.
예시
- tag : 4bits
- index : 4bits
- byte offset : 4bits
라고 가정하자.
index가 4bit이므로, cache의 block 개수는 $2^4(=16)$개 이다.
tag가 4bit이므로, $2^4 : 1$ mapping이다.
byte offset이 4bit이므로, 한 block의 크기가 $2^4$ byte이다.
block의 크기는 16 bytes, 그리고 그 block들이 cache에 16개가 들어있으므로 cache의 크기는 $2^8(=256)$ bytes가 된다.
16:1 mapping이고, cache에는 16개의 block이 들어있므로 main memory에는 총 $16 \times 16 (= 2^{8})$ 개의 block이 들어있다.
따라서 main memory의 크기는 $2^8 \times 2^4 (= 2^{12})$ bytes (= 4KByte)가 된다.
만약 cache memory의 크기를 반으로 줄인다면?
cache memory에는 8개의 block이 존재하게 된다.
cache에서 8개의 block 중 하나만 선택하면 되므로 index는 3bit만 존재하면 된다.
32 : 1 mapping으로 바뀌므로, tag는 5bit으로 증가해야 한다.
block의 크기는 그대로이므로 byte offset은 그대로이다.
만약 block의 크기를 반으로 줄인다면?
한 block에 8byte가 들어간다.
byte offset은 3bit으로 줄어든다.
cache에는 32개의 block이 들어가므로, index는 5bit으로 증가하게 된다.
cache에서 block의 수가 증가하는 배율만큼 main memory에서도 동일하게 증가한다.
때문에 여전히 16:1 mapping이다.
따라서 tag의 bit 수는 그대로이다.
만약 main memory의 크기가 2배로 증가한다면?
main memory의 block의 수가 2배(32개)로 증가한다.
32:1 mapping으로 바뀌므로 tag는 5bit으로 증가한다.
그러나 cache와 block size에는 영향을 주지 않기 때문에 index와 byte offset은 그대로이다.
따라서 전체적인 address는 13bit으로 증가한다.
Cache Simulation
실제 벤치마크를 분석해서 CPU가 어떤 address를 어떤 순서로 내는지를 기록한다.(address trace)
이를 이용해서 hit/miss가 어떻게 나오는지(hit rate) 판단한다.
이후 cache configuration을 바꿔가면서 miss rate를 최대한 줄이도록 개선해야 한다.
- input
- CPU가 주는 addresses
- cache configuration : size, mapping, block size
- output
- cache hit/miss rate
- hit rate는 숫자가 크기 때문에 보통 miss rate를 사용한다.
- cache hit/miss rate
실제 Memory System Design
실제 CPU는 평균적으로 1ns마다 주소 하나를 낸다.
즉 1초에 $10^9$개의 주소를 낸다.
이는 매우 많으므로 실제에서의 분석을 위해서는 sw tool이 필요하다.
예시
5-bit address, 8-byte direct map cache, 1byte/block
tag : 2bits, index : 3bits, byte offset : 0 bit
라고 하자.
5-bit address => main memory = $2^5$ bytes
8-byte direct map cache => cache = 8 bytes
block = 1byte => cache : 8block을 가짐, main memory : 32개의 block을 가짐 => 4:1 mapping
이 예시에서 block size는 편의상 1 byte로 한 것이다.
block size가 더 커도 mapping에는 영향을 주지 않는다.
또한 hit/miss 판단을 위해서는 byte offset이 관여하지 않으므로 byte offset을 0 bit로 함으로써 hit/miss 여부만 볼 수 있다.
위 특성을 파악함으로써 아래와 같이 hit/miss 여부를 파악할 수 있다.

Intrinsity FastMATH
Embedded MIPS processor로 12-stage pipeline을 사용한다.
SPEC2000 분석 결과 다음과 같은 miss rate를 보인다.
- I-cache : 0.4%
- D-cache : 11.4%
- weighted average : 3.2%
I-cache의 miss rate가 D-cache 보다 작은 이유?
Instruction은 보통 sequential하게 동작한다.
따라서 spatial locality가 잘 나타내고 이로 인해 miss rate가 더 낮다.
Weighted Average
Insturction은 매 cycle마다 fetch되기 때문에 매 cycle 마다 I-cache에 접근해야 한다.(거의 100%)
그러나 data는 lw/sw 일 때만 접근하므로 D-cache에는 20%의 확률로 접근한다.
따라서 miss rate의 평균을 구할 때는 weight을 주어야 한다.
(=> 0.4 * 1 + 11.4 * 0.2)
'Computer Science > Computer Architecture' 카테고리의 다른 글
| 5. Write Strategy (0) | 2021.06.11 |
|---|---|
| 5. Set-Associative Mapping (1) | 2021.06.11 |
| 5. Memory Design (0) | 2021.06.11 |
| 5. Cache Memory (0) | 2021.06.06 |
| 5. Memory : Physical, Virtual, Cache (0) | 2021.06.06 |




댓글