ISA Desing Issuses
Instruction은 다음과 같이 이루어진다.
Instuction = operation(opcode) + operand
ISA을 design 할 때에는 opcode, operand, instruction encoding 에 대해서 고민해야 한다.
- operation(opcode)
- 얼마나 많은 종류의 insturction을 만들어야 하는가
- 어떤 종류의 instruction을 만들어야 하는가
- ALU instruction
- Data transfer instruction (LOAD/STORE)
- Branch instruction (IF)
- operand
- addressing mode
- operand의 위치를 어떻게 특정해야 하는가
- regiseter, direct, immdediate
- operand types
- data types
- ALU instruction에는 얼마나 많은 operand가 필요한가
- ADD {operand 1} {operand 2} {operand 3} ...
- addressing mode
- instruction encoding
- instruction의 길이를 어떻게 맞출 것인가
- word 단위로 어떻게 pack할 것인가

ISA Classes
Instruction set에는 대표적으로 5가지의 종류가 존재한다.
필요한 operand의 수, memory address을 operand로 허용하는지 등이 다르다.
그에 따라 같은 기능을 실행하기 위해 필요한 instruction의 개수도 달라진다.
- Stack
- Accumulator
- GRP
- Reigster-Register
- Register-Memory
- Memory-Memory
| Stack = zero-operand architecture |
Accumulator = signle-operand architecture |
GPR | |||
| Register-Register = RISC style |
Register-Memory = CISC style |
Memory-Memory = CISC style |
|||
| C = A + B | Push A Push B Add Pop C |
Load A Add B Store C |
Load R1, A Load R2, B Add R3, R1, R2 Store R3, C |
Load R1, A Add R3, R1, B Store R3, C |
Add C, A, B |
| 4개 | 3개 | 4개 | 3개 | 1개 | |
| ALU의 메모리 접근 | 허용 | 허용 | 0개 | 1개 | 3개 / 2개 (instruction을 더 짧게 만들어야 할 때는 2 operation 사용) |
| 특징 | Stack에서 병목현상 발생 | AC에서 병목현상 발생 | |||
Stack ISA
zero-operand architecture라고도 한다.
Stack을 통해서만 메모리에 접근할 수 있다.
따라서 연산할 때 모든 데이터들은 stack을 통해야 한다.
때문에 operand가 줄어들고, ALU instruction에 있어서는 operand가 필요 없다.
그러나 stack에서 병목현상이 발생하게되고, 이로인해 성능 저하가 일어난다.
다음과 같은 구조로 프로세서가 구성된다.
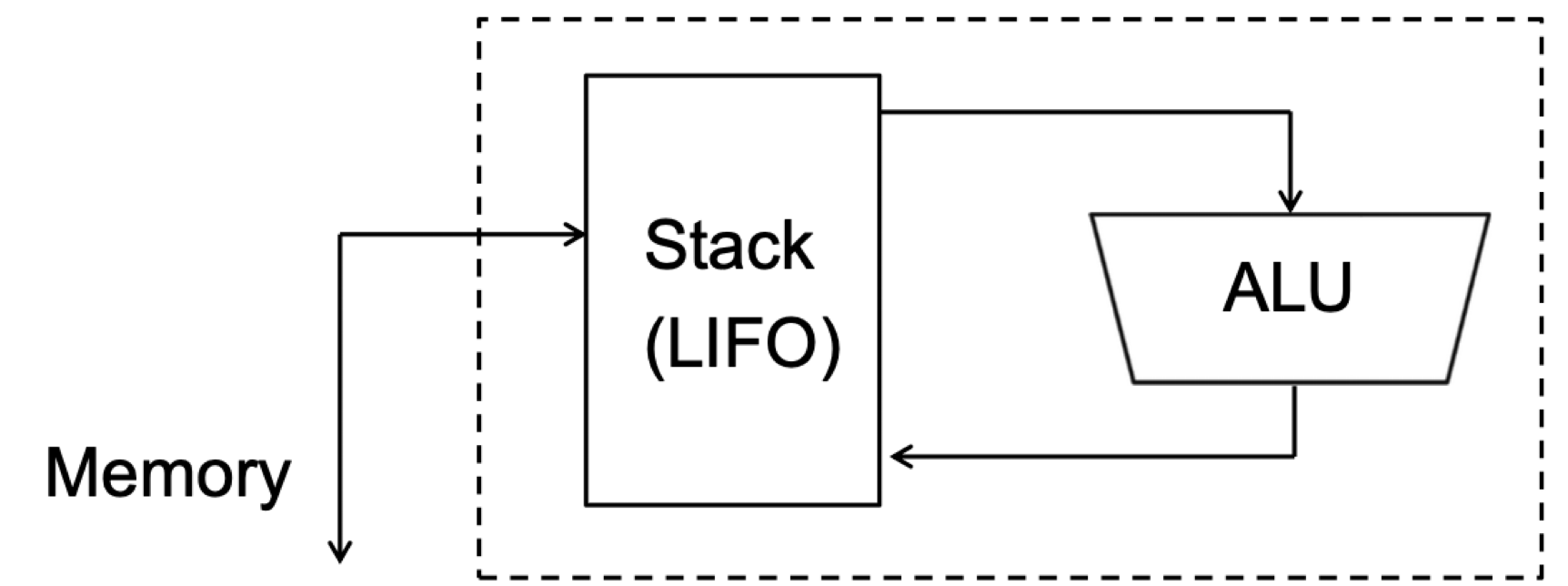
<pre>C = A + B</pre>의 연산 수행은 다음과 같이 이루어진다.
<pre>
Push A
Push B
Add
Push C
</pre>
ALU는 stack을 이용해서 연산을 처리한다.
Operand가 생략된 부분은 stack의 최상위와 관련되어 있다.
Add의 경우 stack의 최상위에 있는 2개를 pop한 후 연산하여 다시 stack에 집어넣는다.
Pop은 stack의 최상위에 있는 것을 빼서 operand로 넘어온 주소에 저장한다.

Accumulator ISA
Single-operand architecture라고도 한다.
모든 연산은 AC(accumulator) 통해서 이루어진다.
때문에 AC에서 병목현상이 발생하게되고, 성능이 저하된다.
다음과 같은 구조이다.
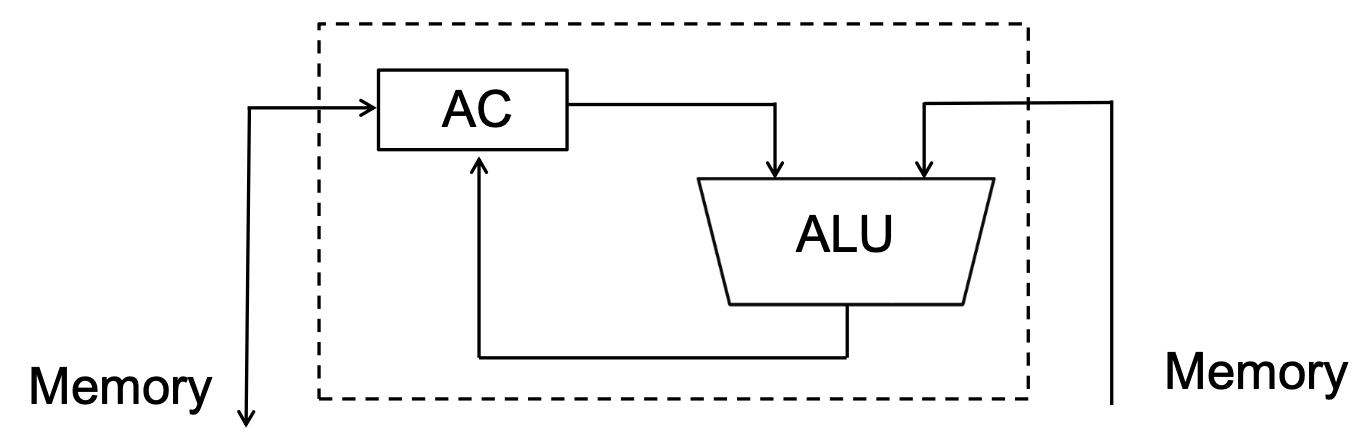
ALU은 AC을 이용해서 연산을 처리한다.
생략된 operand가 생략된 부분은 모두 AC와 관련있다.
<pre>C = A + B</pre>은 다음과 같이 수행된다.
<pre>
Load A // AC <- M[A] : A 번지에 있는 내용을 AC에 저장한다.
Add B // AC <- AC + M[B] : B번지의 내용을 AC와 더하고, 그 결과를 다시 AC에 저장한다.
Store C // C <- AC : AC의 내용을 C번지에 저장한다.
</pre>
GPR ISA
General-Purpose-Register(범용 레지스터)을 이용하는 구조이다.
범용 레지스터는 응용프로그램을 실행하기 위핸 레지스터이다.
응용프로그램이 실행하는데 있어서 필요한 데이터나 실행 도중 발생하는 중간 결과를 저장한다.
레지스터는 캐시와 같은 역할을 한다.
프로그램 실행을 위한 데이터를 미리 담아놓을 수 있어서, 데이터를 여러 번 사용하는 경우에는 매번 메모리에서 데이터를 가져오지 않아도 된다.
이는 메모리에 접근해야하는 횟수를 줄여서 메모리 트래픽을 줄인다.
연산 중에 어떤 레지스터에 데이터를 저장할 것인가는 컴파일러가 결정한다.
만약 ALU를 여러 개 붙여서 병렬처리를 통해 연산 속도를 높이기 위해서는 데이터를 동시에 처리해야하기 때문에 더 많은 레지스터가 필요하게 된다.
즉, high-speed processor을 위해서는 많은 레지스터가 필요하다.
아래와 같이 프로세서가 레지스터를 갖는 것이 기본 구조이다.
ALU가 레지스터로만 데이터가 접근이 가능한지, 메모리로도의 직접적인 접근이 가능한지에 따라서 종류가 나뉜다.
- Register-Register architecture
- Register-Memory architecture
- Memory-Memory architecture

Register-Register Architecture
메모리는 register을 통해서만 접근이 가능하다.
즉, 모든 데이터는 register을 통해서 접근되고 ALU은 register만을 이용해서 연산을 수행한다.
Load-Store Architecture라고도 한다.
- 메모리로는 Load/Store을 통해서만 접근이 가능하다.
- 모든 ALU instrcution은 register 기반이다.
RISC architecture는 register-register architecture이다.
오늘날 intel x86을 제외한 모든 컴퓨터는 RISC style인데, intel x86 또한 내부적으로는 RISC style을 사용한다.
Register-Register architecture는 다음과 같은 구조를 가진다.

<pre>C = A + B</pre>의 연산은 다음과 같이 수행된다.
<pre>
Load R1, A // R1 <- M[A]
Load R2, B // R2 <- M[B]
Add R3, R1, R2 // R3 <- R1 + R2
Store R3, C // M[C] <- R3
</pre>
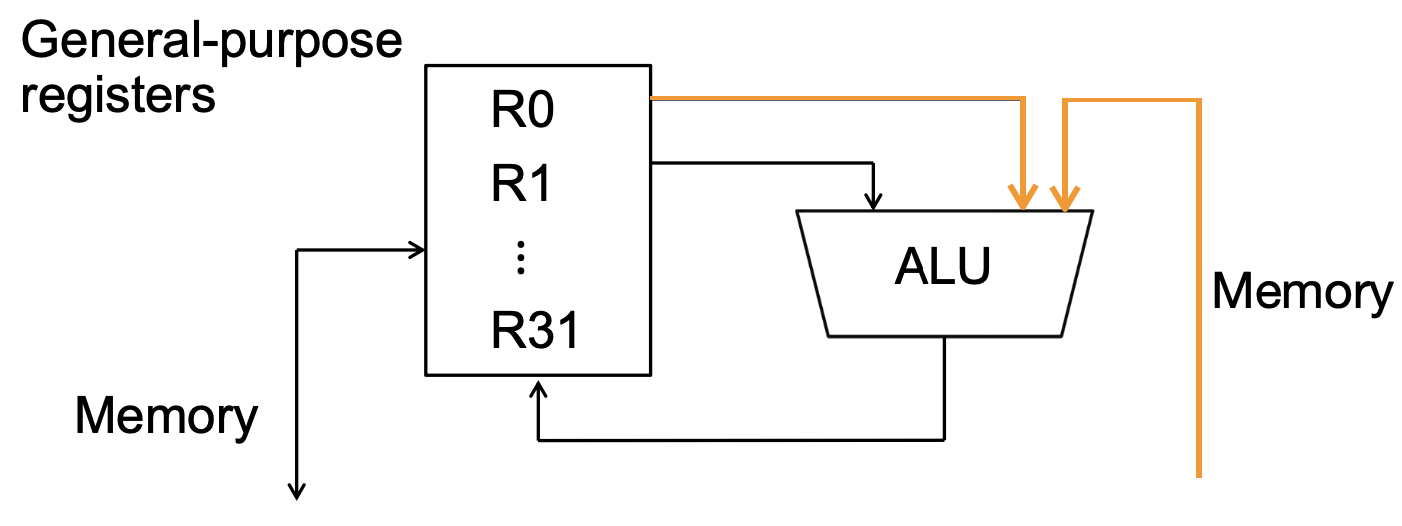
Register-Memory Architecture
ALU가 메모리에 접근하는 방식이 레지스터를 이용한 것 + 직접 접근 이다.
데이터를 메모리에서 직접 가져올 수 있다.
다만 메모리에 write하는 것은 레지스터를 이용해야 한다.
<pre>Add R3, R1, A</pre>와 같이 메모리에 직접 접근하는 ALU instruction도 처리할 수 있다.
당연히 <pre>Add R3, R1, R2</pre>와 같은 R-R 방식도 처리할 수 있다.
이는 하나의 instruction이 더 많은 일을 수행할 수 있음을 말한다.
즉 instruction(ISA)이 조금 더 complex해진 것이다.
따라서 같은 일의 양을 처리하기 위해서 더 적은 instrution이 사용된다.
<pre>C = A + B</pre>의 연산 수행은 다음과 같이 처리될 수 있다.
<pre>
Load R1, A // R1 <- M[A]
Add R3, R1, B // R3 <- R1 + M[B]
Store R3, C // M[C] <- R3
</pre>
Memory-Memory Architecture
CISC style architecture가 memory-memory architecture이다.
오늘날에는 RISC에 비해서 성능이 떨어지기 때문에 사용되지 않는 방식이다.
ALU가 데이터를 register와 메모리를 통해서 가져올 수 있고, 메모리에 직접 write 할 수 있다.
R-R, R-M architecture의 instruction을 포함하여 지원한다.
따라서 instruction은 더 complex 해졌다.
그리고 같은 일을 처리하는데 있어서 더 적은 수의 instruction으로 처리가 가능했다.

<pre>C = A + B</pre>의 연산 수행은 다음과 같다.
<pre>
Add C, A, B // M[C] <- M[A] + M[B]
</pre>
CISC v.s. RISC Style Architecture
CISC
Operation과 addressing mode가 다양하다. 간단한 것도 있고 복잡한 것도 있다.
Addressing mode에는 register-memory, memory-memory 방식 등이 있다.
Instruction의 구조, 기능, 실행시간, 길이 등이 매우 다양하다.
예전에는 메모리가 비쌌고, 그로 인해 disk에 비해 memory의 크기가 작았다.
프로그램 실행은 disk drive에 있는 executable file을 메인 메모리에 올림으로써 이루어졌다.
그런데 disk에 executable file 전체를 메모리에 올릴 수 없었다.
따라서 executable file의 일부분을 메인 메모리에 올려서 실행하고 그 실행이 끝나면 disk I/O을 통해서 executable의 다른 부분으로 교체해서 실행하였다.
이로 인해 I/O time for code는 매우 증가하였다.
더 빠른 성능을 위해서 executable file의 크기를 줄여야 했고, 그를 위해서 code density을 증가시켰다.
Register-memory, memory-memory architecture 등과 같이 더 많은 기능을 하는 instruction들을 사용한 것이다.
CISC는 상황에 따라서 가장 compact한 instruction을 사용한다.
high code density, smaller executable file을 위한 것이다.
RISC
CISC에 비해
- fewer operation
- fewer addressing mode
- fixed and easy-to decode instruction format (fetch을 적게해도 되기 때문)
의 장점을 가졌다.
그리고 다음과 같은 특징을 지닌다.
- single cycle execution (pipeline을 이용하면 CPI ≒1)
- use of optimizing compilers (IC을 줄이기 위함)
- access memory only through Load/Store
RISC vs CISC
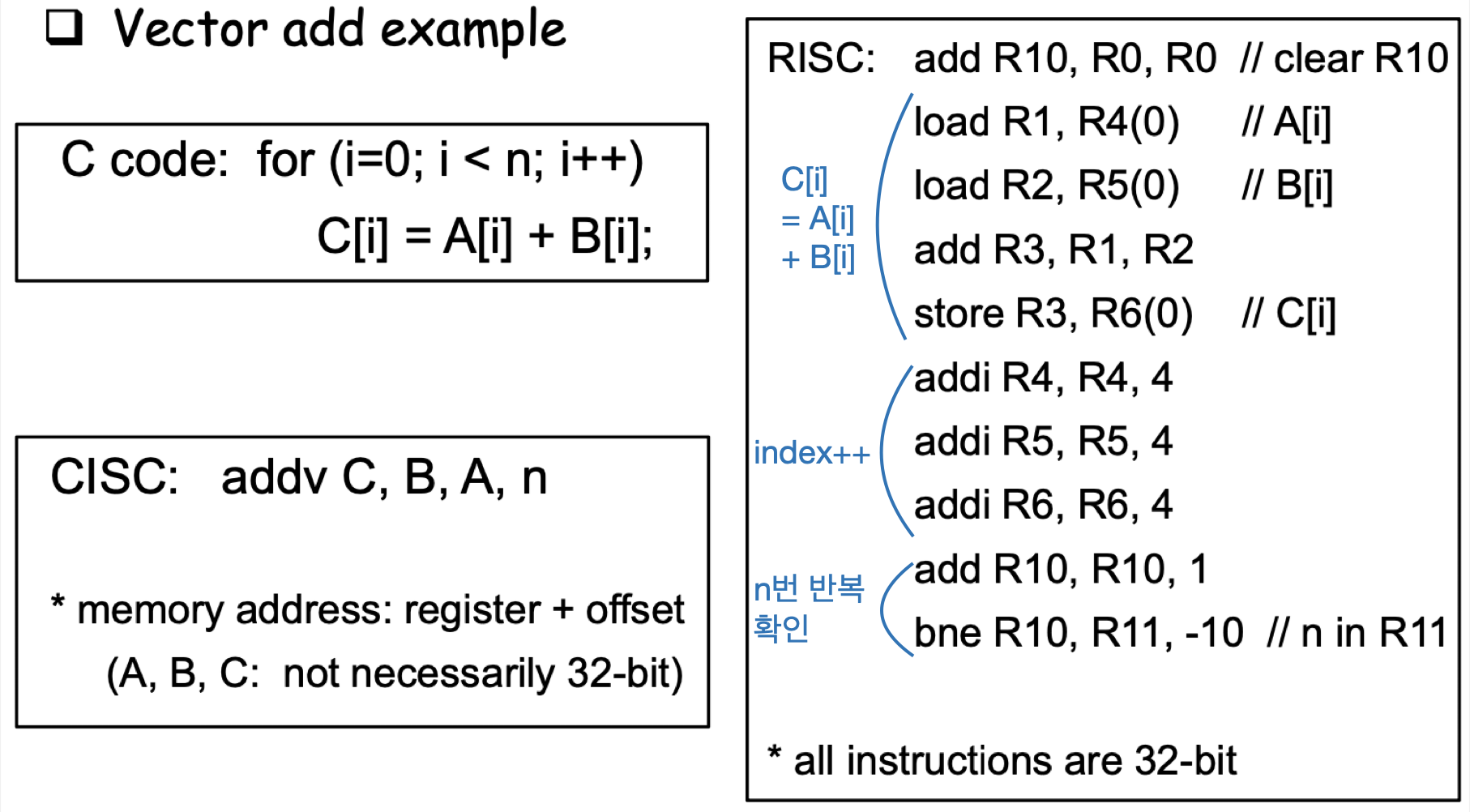
예시 1
<pre>C = A + B</pre>을 수행하기 위해서 RISC style은 다음과 같은 처리만 가능하다.
<pre>
load R1, A
load R2, B
add R3, R1, R2
store R3, C
</pre>
그러나 CISC style은 다음과 같이 다양한 구조로 만들 수 있다.
상황에 따라 가장 compact한 instruction을 채택한다.
<pre>
| 1. | 2. | 3. | 4. |
| add1 R1, A, B | load R2, B | load R2, A | add4 C, A, B |
| store C, R1 | add2 C, A, R2 | add3 C, R2, B | |
</pre>
만약 4번과 같은 방식을 채택한다면 CISC는 RISC에 비해 executable file의 크기가 2배 더 작게 될 것이다.
(RISC : 4 words, CISC : 2 words)
예시 2
CISC style은 상황에 따라 executable file의 크기를 줄이기에 적합한 instruction을 새로 만들어서 적용하기도 한다.
CISC의 쇠퇴 및 RISC
반도체 기술(semiconductor technology)이 발전함에 따라 메모리의 용량은 exponential하게 커져갔고 가격도 저렴해졌다.
따라서 executable file의 크기가 더 이상 작지 않아도 되었다.
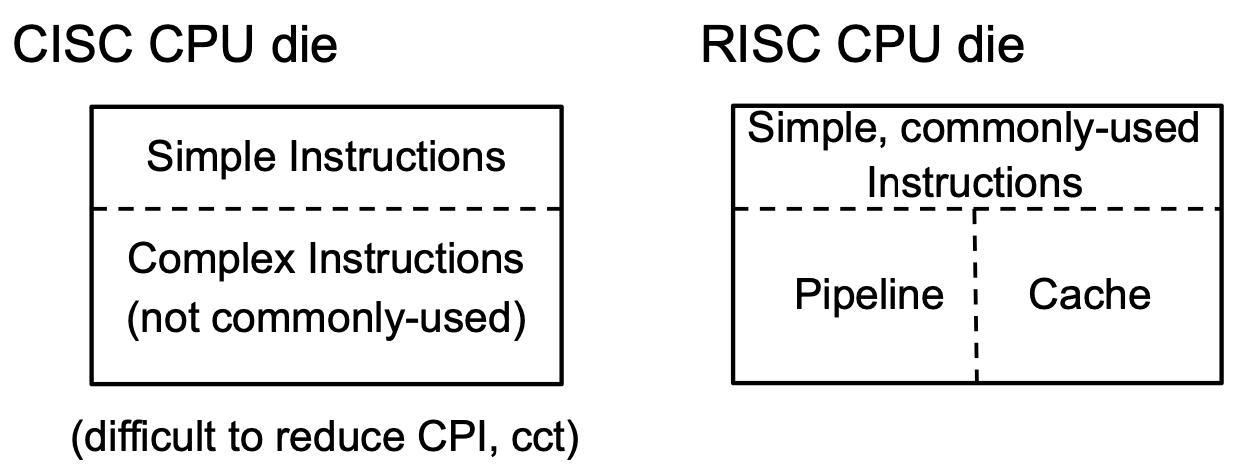
Operation과 addressing mode의 종류가 많아질수록 구현하기 위한 하드웨어가 많이 필요하고 die area의 크기가 커져만 갔다.
그리고 복잡한 instruction일 수록 자주 사용되지 않았다.
pipelining과 같이 efficient implementation은 CISC style에 적용하기 힘들다.
이에 따라 CPI와 cct는 RISC에 비해 훨씬 컸고 성능에 있어서 뒤쳐졌다.
RISC는 단순한 instruction들만 넣어놓고, 이를 여러개 조합함으로써 복잡한 instruction을 수행한다.
따라서 die에서 compelx instruction의 공간이 불필요해졌고 이 die area를 pipeline과 cache와 같이 efficient implementation을 위해 사용하였다.
x86 Architecture
오늘날 대부분의 ISA는 RISC style architecture이다.
그러나 x86은 CISC style이다.
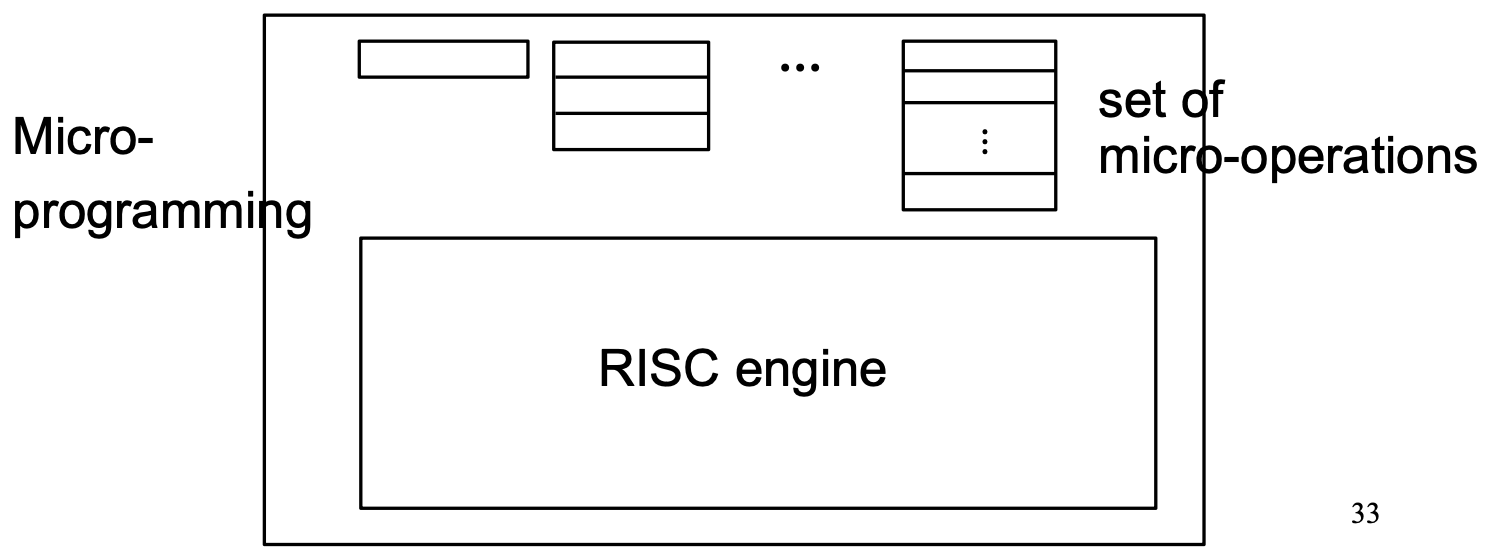
RISC style에 비해 뒤떨어지는 CISC style을 이용하여 속도를 높이기 위해 x86은 내부적으로 RISC 방식을 사용한다.
즉 많은 기능을 하는 instruction들은 set of micro-operation로, micro-operation들로 이루어졌다.
Micro-operation들은 각각 RISC instruction이다.
이러한 방법을 micro-programming이라 한다.
'Computer Science > Computer Architecture' 카테고리의 다른 글
| 2. MIPS Instruction Set (0) | 2021.04.17 |
|---|---|
| 1. Multicore (0) | 2021.04.10 |
| 1. 컴퓨터 성능 개선/결정 (How to improve) (0) | 2021.04.03 |
| 1. 컴퓨터 성능 (What to Measure, How to Measure) (0) | 2021.04.03 |
| 성능을 위한 ISA 구현 방법(간략) (0) | 2021.03.27 |




댓글